Previous: L10 — GANs | Back to MPL Index | Next: (y-12) Diffusion
University of Stuttgart — Machine Perception and Learning for Collaborative Intelligent Systems, Prof. Dr. Andreas Bulling, WS 2025/2026
Goal of this lecture: Go from first principles all the way to PPO — one of the most widely used RL algorithms today.
Mental Model First
- RL is about delayed credit assignment: an action now may only reveal its value much later.
- Value functions estimate how promising a state or action is in the long run; policies decide what to do next.
- Many RL algorithms differ mainly in how they trade off exploration, stability, variance, and sample efficiency.
- If one question guides this lecture, let it be: how do we learn from sparse, delayed rewards when the correct action is not labeled for us?
Introduction
Three Paradigms of Learning

The three paradigms: supervised, unsupervised, and reinforcement learning.
| Paradigm | How it learns | Data |
|---|---|---|
| Supervised Learning | Learn a mapping from input to output | Ground truth labels available |
| Unsupervised Learning | Learn the structure of a dataset | No ground truth |
| Reinforcement Learning | Data revealed through interacting with an environment | Learn how to act |
Informally:
- SL: “This is a cat.”
- UL: “These two images look similar.”
- RL: “This cat likes to be scratched behind the ears.” (discovered through interaction)
The RL Problem

Reinforcement learning: learning through trial and error.
Reinforcement learning is learning to solve sequential decision problems via repeated interaction with an environment (trial and error).
Three questions to answer:
- What is a sequential decision problem? → MDP
- What does it mean to “solve” it? → Maximise total reward
- What is learning by interaction? → TD / Policy Gradient
The Agent–Environment Loop

The RL loop: agent and environment in a constant exchange.
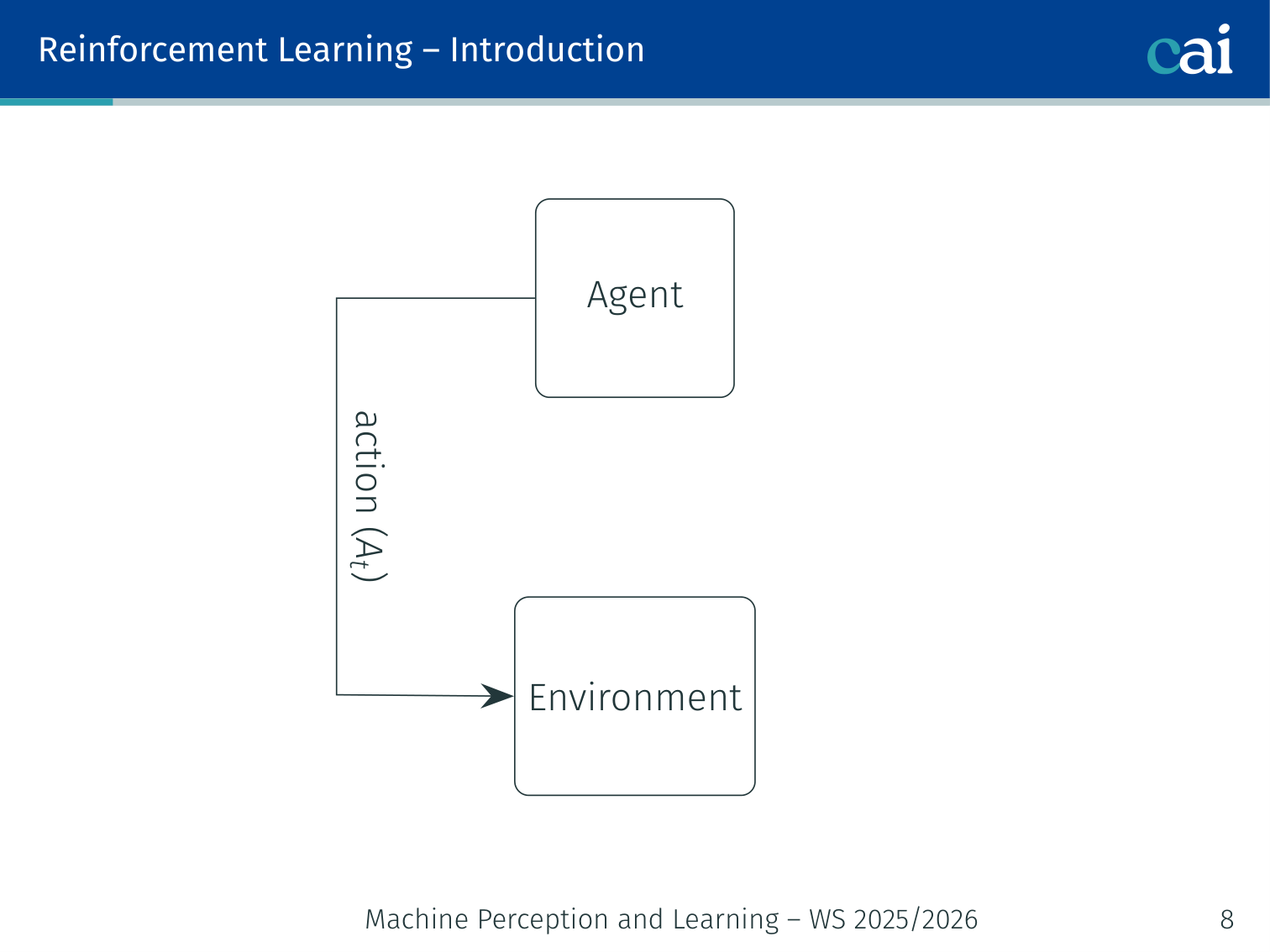
A simple diagram of how state, action, and reward flow in RL.
+-----------------------------------+
| Agent |
| Policy π(a|s) |
+----------------+------------------+
| action (At)
v
+-----------------------------------+
| Environment |
| state (St) reward (Rt) |
+-----------------------------------+At each timestep :
- Agent observes state
- Agent selects action
- Environment transitions to and emits reward
- Agent uses to update its policy
💡 Intuition: Reinforcement Learning as “Puppy Training”
Imagine you are teaching a puppy to sit.
- Observation: The puppy is standing (the State).
- Action: The puppy sits down (the Action).
- Reward: You give it a treat (the Reward).
- Learning: Next time the puppy is in that state, it’s much more likely to sit because it remembers the treat.
The important thing is that you never tell the puppy how to move its muscles. You just reward the outcome. This is why RL is so powerful for things like walking robots — we don’t have to program the exact movement; the robot “discovers” it through trial and error.
🧠 Deep Dive: Why the “Advantage” Function?
In basic Policy Gradient (REINFORCE), we use the total reward to tell the model: “This whole episode was good.”
The Problem: Some actions in a good episode might actually have been bad. (E.g., you won a game of chess, but you made one terrible move in the middle).
The Solution: The Advantage Function .
- It doesn’t just ask: “Was this a good action?”
- It asks: “Was this action better than average for this state?”
If the average reward for being in state is 10, and your action leads to a reward of 12, the Advantage is . If it leads to 8, the Advantage is (even though 8 is still positive!). This tells the model to only boost the actions that outperform our current expectations.
Markov Decision Process (MDP)
Formal Definition
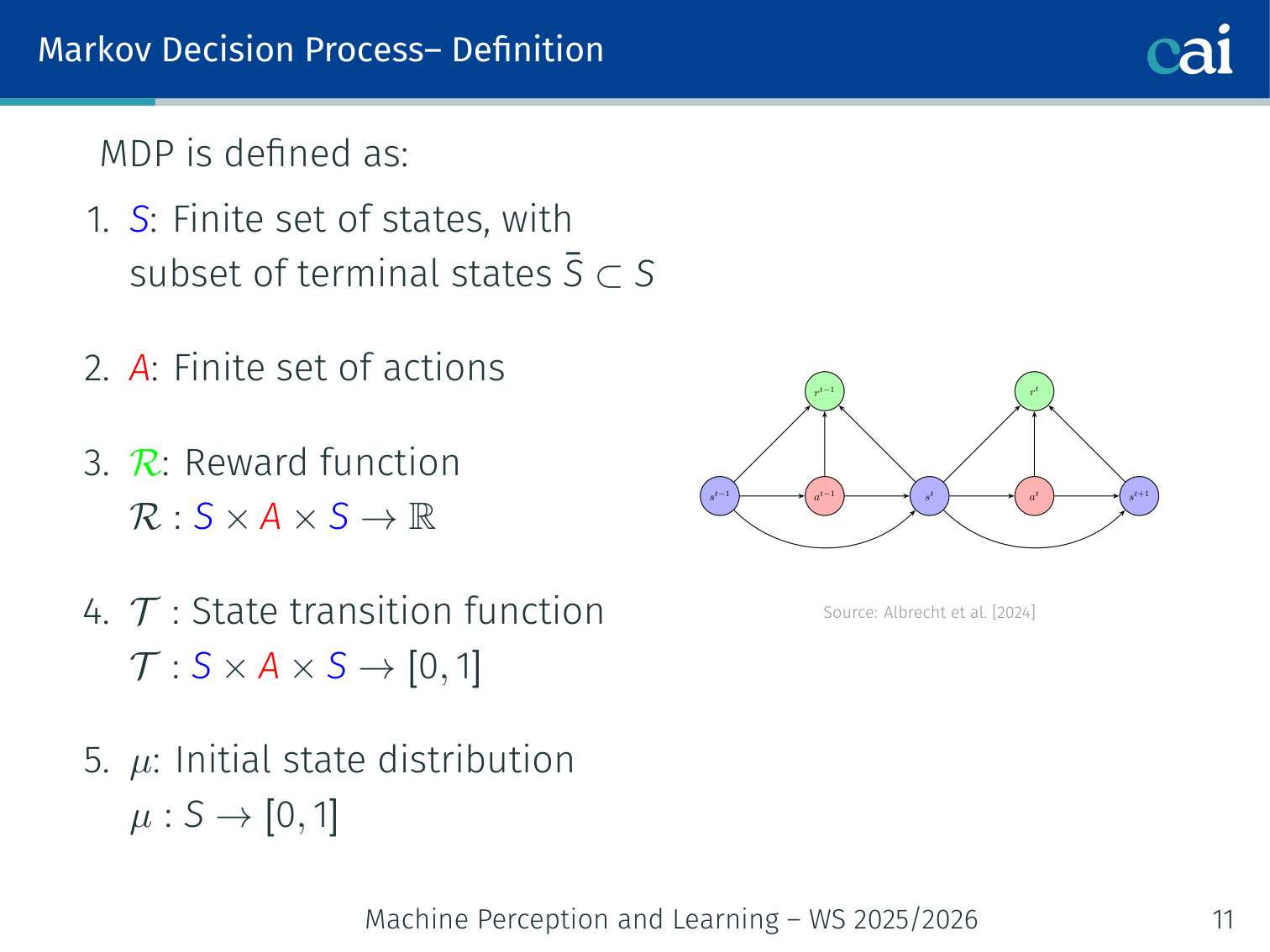
A formal look at MDPs: the foundation of RL math.
An MDP is the tuple :
| Symbol | Meaning |
|---|---|
| Finite set of states (with terminal subset ) | |
| Finite set of actions | |
| Reward function | |
| State-transition function | |
| Initial state distribution |
The Markov property: the future depends only on the current state, not history:
Expected Discounted Return

Calculating the expected return, with a bit of a discount for the future.
The goal is to learn a policy that maximises the expected discounted return:
- : myopic — only cares about immediate reward
- : far-sighted — weights all future rewards nearly equally
Example: Rewards of forever. With : . Without discounting the sum diverges.
Value Functions
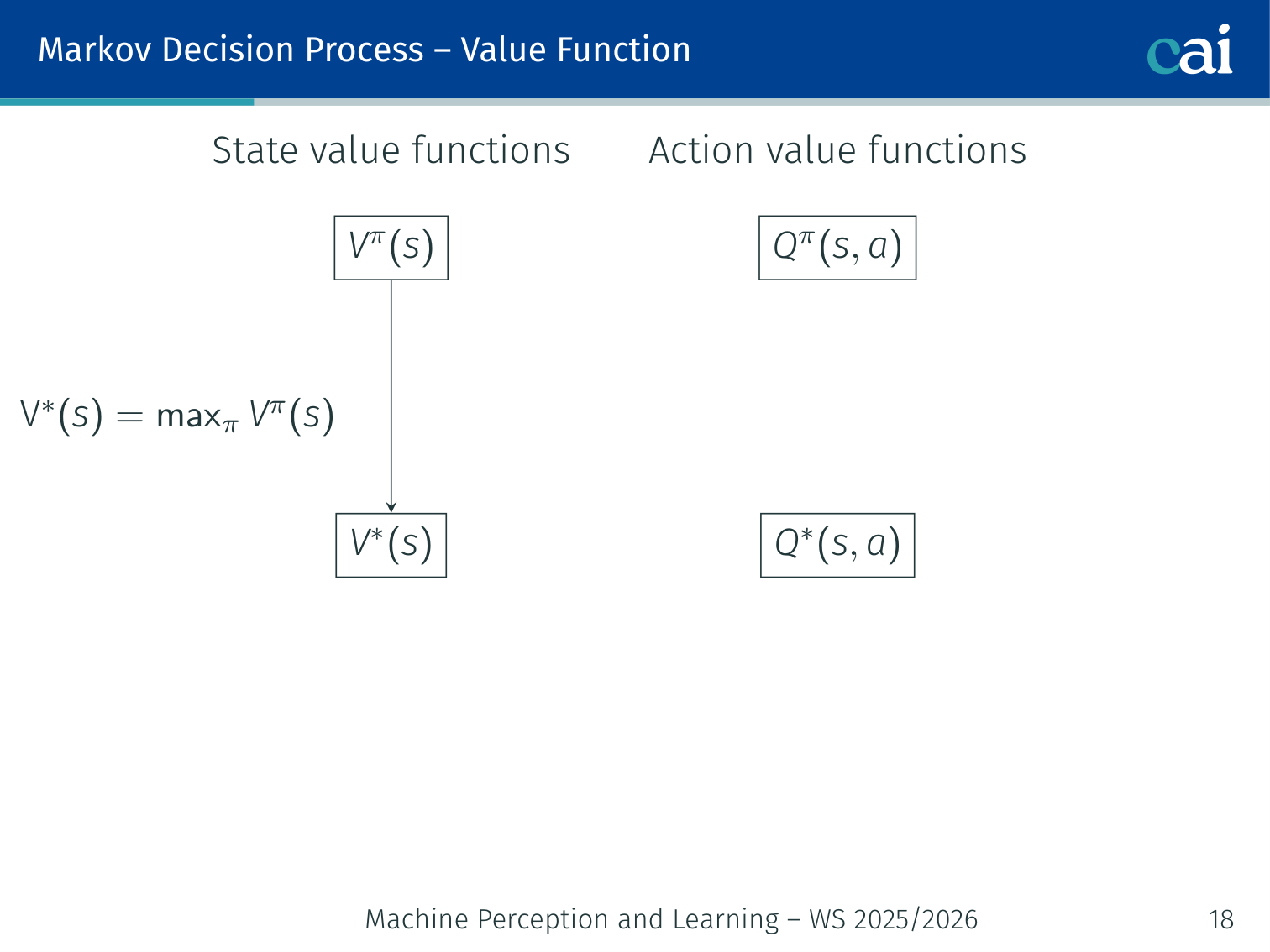
Value functions: what's a state or action actually worth?
State-value function:
Optimal:
Action-value function:
Optimal:
Key relationships:
Optimal policy derived from :
Or via one-step look-ahead using :
Bellman Equation
The return decomposes recursively: . Taking expectations:
We can solve for iteratively:
💡 Intuition: Bellman Means “Immediate Reward + Future Promise”
The Bellman equation says the value of a state is not mysterious. It is just:
- what you expect to get right now
- plus what you expect the next state to be worth
That is why RL can use bootstrapping. Instead of waiting until the whole future has happened, it can reuse its current guess of the future as part of the target.
Sutton and Barto describe this as a recursive relationship between a state and its successor states. That recursive structure is the backbone of dynamic programming, TD learning, Q-learning, and actor-critic methods.
Dynamic Programming

Using Dynamic Programming to solve MDPs when we know how the world works.
When the full model is known, we can find the optimal policy exactly.
Methods Overview
| Method | Requires model? | How it works |
|---|---|---|
| Dynamic Programming | Yes | Iterate over all states using the model |
| Monte-Carlo | No | Full trajectory rollouts |
| Temporal-Difference | No | Bootstrap from visited states |
Policy Iteration

Policy Iteration: evaluating and then improving our policy step by step.
- Policy Evaluation: compute for current
- Policy Improvement: update greedily w.r.t.
Guaranteed to converge to in finite iterations.
Value Iteration

Value Iteration: searching for the best possible value function.
Apply the Bellman optimality equation as an update:
Algorithm:
Initialize V(s) = 0 for all s in S
repeat:
for all s in S:
V(s) <- max_{a} sum_{s'} p(s'|s,a) [r(s,a,s') + gamma*V(s')]
until V converged
pi*(s) = argmax_a sum_{s'} p(s'|s,a) [r(s,a,s') + gamma*V*(s')]
GridWorld Example (, step cost )
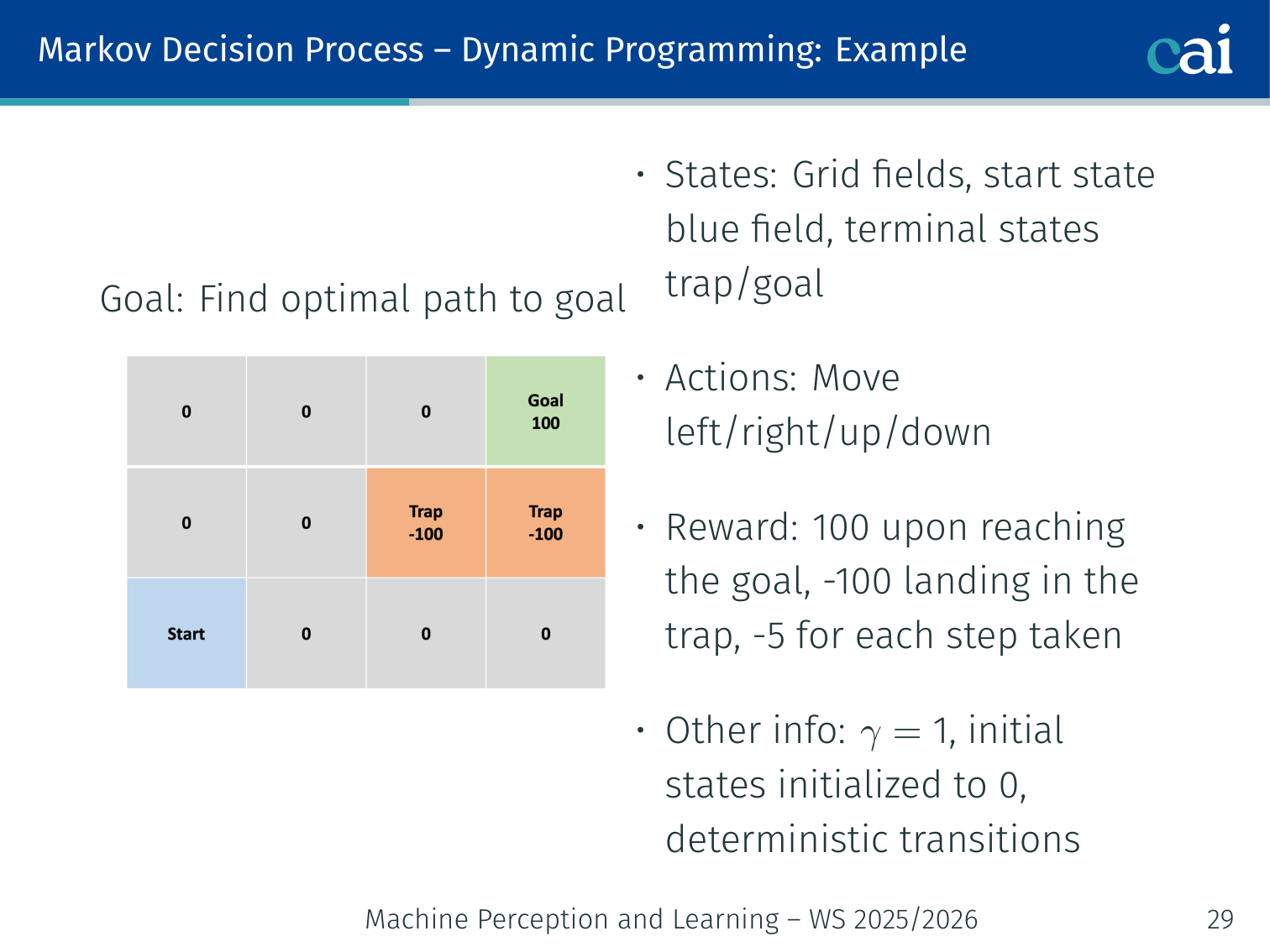
GridWorld: seeing how values propagate when every step has a cost.
4×4 grid: goal , trap , step cost . Deterministic transitions.
| Iteration | Effect |
|---|---|
| 0 | All |
| 1 | Goal gets , trap gets . Adjacent cells update. |
| 2–5 | Values propagate outward from goal and trap. |
| 6 | Convergence — no further change. Greedy policy gives optimal path. |
Intuition: value iteration “floods” the grid outward from the goal and trap. States close to the goal converge first; farther states feel the reward signal later.
Pros and Cons of Dynamic Programming

The pros and cons of using Dynamic Programming for RL.
| ✅ Exact — guaranteed convergence to | |
| ✅ Value iteration more efficient than policy iteration | |
| ❌ Requires full model | |
| ❌ Must iterate over all — infeasible for large/continuous spaces | |
| ❌ Memory proportional to |
When state space is too large → Temporal-Difference learning.
Temporal-Difference (TD) Learning
Core Idea
Only update visited states. Use bootstrapping: use current value estimates as targets without waiting for the episode to end.
For each step from via action to :
Exploration vs. Exploitation

The exploration-exploitation tradeoff: trying new things vs. sticking to what works.

Exploration strategies: a look at how epsilon-greedy works.
| Strategy | Description | Drawback |
|---|---|---|
| Random (pure exploration) | Choose randomly every step | Wastes effort on known bad states |
| Greedy (pure exploitation) | Always take highest-Q action | Gets stuck in local optima |
| -greedy | Random with prob. ; greedy otherwise | Good practical balance |
is typically annealed from down to a small value (e.g., ) over training.
Two Major Implementations
SARSA (On-Policy TD)

SARSA: a classic on-policy way to learn from temporal differences.
Uses the next action actually taken by the same policy:
On-policy: the data-collection policy = the policy being updated. Because SARSA factors in the actual (possibly random) next action, it tends to be more cautious near dangerous states.
Example: Agent uses -greedy. In state it randomly picks . SARSA updates using that random , learning the value of the -greedy policy itself — not the optimal one.
Q-Learning (Off-Policy TD)

Q-Learning: the go-to off-policy method for TD learning.
Uses the best possible next action regardless of what the exploration policy would take:
Off-policy: data collected via -greedy, but updates use the greedy max — converges directly to .
💡 Intuition: SARSA Learns the Policy You Actually Use, Q-Learning Learns the Policy You Wish You Had
This is one of the most important conceptual splits in classical RL.
- SARSA asks: “given that I really do explore and sometimes make random moves, how good is this action?”
- Q-learning asks: “if I behave optimally from the next state onward, how good would this action be?”
That is why Q-learning is often more aggressive. It evaluates actions under the optimistic assumption that future choices will be greedy, while SARSA evaluates them under the actual exploratory behavior of the current policy.
SARSA vs. Q-Learning:
| SARSA | Q-Learning | |
|---|---|---|
| Type | On-policy | Off-policy |
| Update target | — actual next action | — best possible |
| Converges to | ||
| Risk behaviour | Cautious near danger | More aggressive during training |
Worked Example: Q-Learning (, step cost , )
3x3 GridWorld. Goal at (2,2): reward +1. All Q = 0 initially.
Episode 1:
s=(0,0), random "right" -> s'=(0,1), r=0
DeltaQ = 0 + 1.0 * max Q(0,1,.) - 0 = 0 [no update yet]
Episode 2:
... -> s=(1,2) "down" -> s'=(2,2), r=+1 (goal!)
DeltaQ[(1,2), down] = 1 + 0 - 0 = 1.0
Q[(1,2), down] <- 0 + 0.1 * 1.0 = 0.1
Episode 3:
s=(0,2) "down" -> s'=(1,2)
DeltaQ[(0,2), down] = 0 + 1.0 * 0.1 - 0 = 0.1
Q[(0,2), down] <- 0 + 0.1 * 0.1 = 0.01
After many episodes: Q-values converge; greedy policy traces shortest path to goal.
TD Learning: Pros and Cons

Weighing the pros and cons of TD learning methods.
| ✅ No model needed — does not require | |
| ✅ Online updates — learn after every step | |
| ✅ Lower variance than full Monte-Carlo | |
| ❌ Biased — bootstrapping introduces bias | |
| ❌ Exploration vs. exploitation dilemma | |
| ❌ Can behave poorly in stochastic environments |
Deep Reinforcement Learning
Motivation: Tabular Methods Fail at Scale
- Learn each pair independently — no generalisation
- For raw image inputs (e.g., Atari frames), is astronomically large → Q-table impossible to store
Solution: approximate or with a neural network.
Deep Q-Networks (DQN)

DQN: bringing the power of neural networks to Q-learning.
Use a neural network . The Q-learning update becomes SGD on:
- = target network (frozen copy of , periodically synced for stability)
Experience Replay

Experience Replay: how we break correlations to stabilize DQN training.
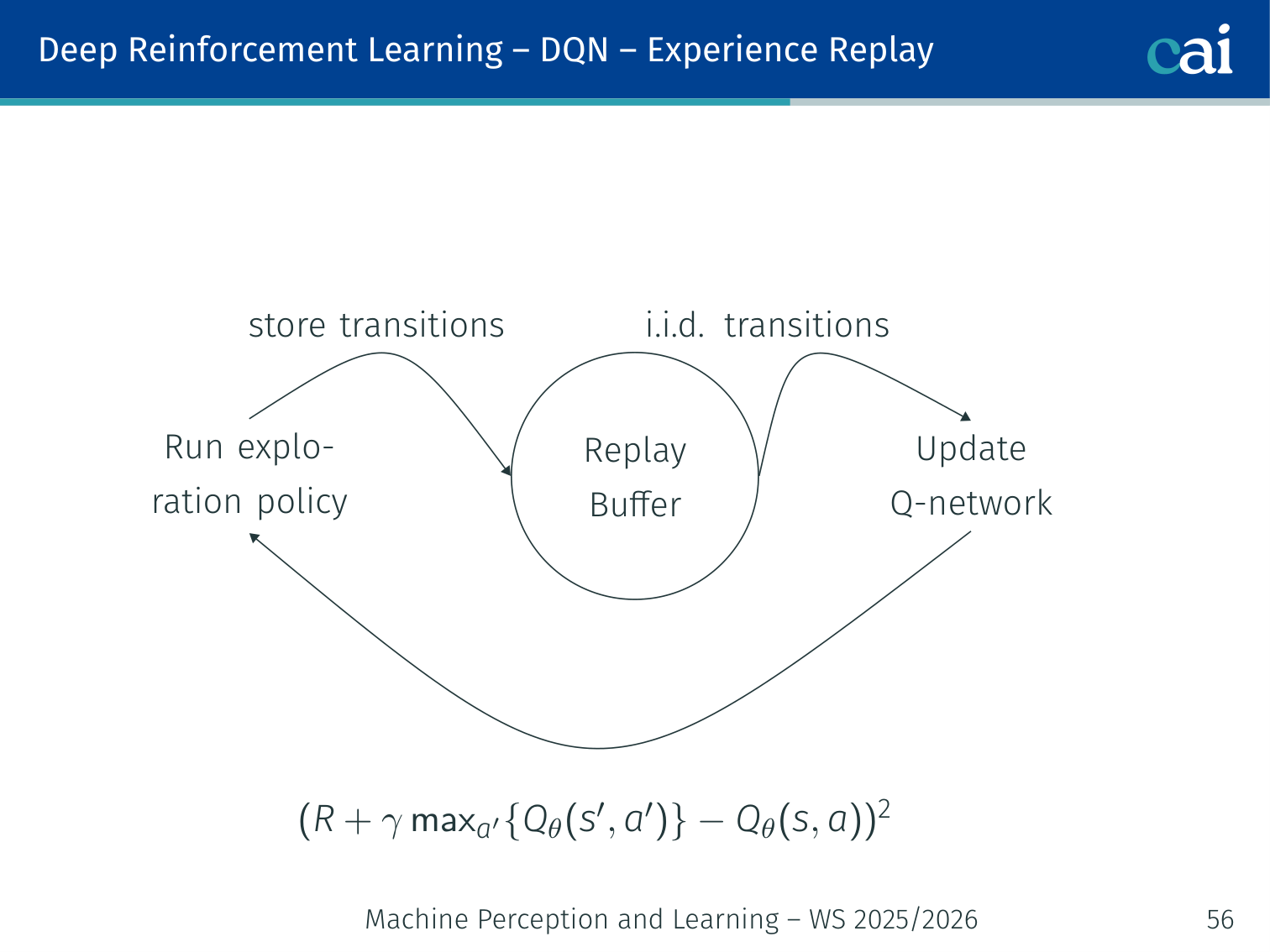
The replay buffer: sampling mini-batches to learn more efficiently.
Problem: consecutive transitions are strongly correlated — violates SGD’s i.i.d. assumption.
Solution: store transitions in a replay buffer, sample random mini-batches for updates.
Run eps-greedy -> store (s, a, r, s') in Replay Buffer
|
Sample i.i.d. mini-batch
|
Update Q-network via SGD on
(r + gamma * max_{a'} Q_tbar(s',a') - Q_t(s,a))^2
Q-learning is off-policy → old buffer samples remain valid.
DQN Architecture (Atari)

The DQN architecture that famously mastered Atari games.
Input: 4 stacked grayscale frames (84x84x4)
-> Conv(8x8, 32 filters, stride=4) -> ReLU
-> Conv(4x4, 64 filters, stride=2) -> ReLU
-> Conv(3x3, 64 filters, stride=1) -> ReLU
-> Flatten -> Dense(512) -> ReLU
-> Dense(num_actions) <- one Q-value per discrete action
Achievement: the DQN line of work showed that one architecture could learn directly from raw Atari pixels across many games. The widely cited superhuman Atari result is from the later Nature paper by Mnih et al. (2015).
DQN Key Tricks
A few essential tricks to keep DQN training from falling apart.
| Trick | Why |
|---|---|
| Experience Replay | Break temporal correlations; reuse transitions efficiently |
| Target Network | Stable training targets; prevent oscillations |
| ε-greedy | Balance exploration/exploitation during training |
Limitation: DQN requires a discrete action space (one Q-value output per action).
Policy Gradient Methods

Policy Gradients: optimizing the policy directly instead of just values.
Instead of learning and deriving , directly optimise by gradient ascent on expected return.
Policy Evaluation
A trajectory is sampled from:
Performance measure:
Objective: , updated via .
Policy Gradient Derivation

The log-probability trick: a key step in deriving policy gradients.

Wrapping up the derivation for the Policy Gradient theorem.
Since transition dynamics are independent of :
Policy gradient theorem:
Key property: no knowledge of environment dynamics needed — only the policy and sampled rewards.
💡 Intuition: Why the Log-Probability Trick Works
This update can look magical the first time you see it. In plain language, it says:
- if an action appeared in a high-return trajectory, increase its log-probability
- if it appeared in a low-return trajectory, decrease its log-probability
The term
points in the direction that would make action more likely in state . Multiplying by return tells us whether that push should be positive or negative.
So policy gradients are basically weighted imitation of your own past behavior, where the weights come from how well that behavior turned out.
REINFORCE (Monte-Carlo Policy Gradient)

REINFORCE: using Monte-Carlo sampling to update our policy.
Sample full trajectory rollouts then update:
Must complete full episodes before updating.
Intuition: high-return trajectories get their action probabilities boosted; bad ones are suppressed. “If it worked, do more of it.”
Variance Problem and Baseline

Using a baseline to keep policy gradient variance in check.

Subtracting a baseline: less noise, same unbiased gradient.
Monte-Carlo sampling → noisy gradients (few samples, high variance).
Fix: subtract a baseline that is independent of (keeps gradient unbiased):
Common choices:
- Average reward across the batch
- State-value function → advantage
Actor-Critic

Actor-Critic: combining policy (actor) and value (critic) estimation.

Using TD error to estimate the "advantage" in Actor-Critic.
Reduce variance further (with some bias) by using bootstrapping instead of full returns:
This is the advantage function with a bootstrapped estimate:
Architecture:
State s
|
+------+------+
| |
Actor Critic
(pi_theta) (V_phi)
a ~ pi(.|s) V(s) -> compute A_hat_t
- Actor: policy network , updated by gradient ascent using
- Critic: value network , updated by minimising
Most SOTA RL algorithms build on actor-critic.
💡 Intuition: Actor-Critic Splits “What To Do” From “How Good It Was”
Actor-critic is easier to remember if you personify the two parts:
- Actor = the decision-maker
- Critic = the evaluator
The actor proposes actions. The critic estimates whether the current situation is better or worse than expected. The TD error then becomes a training signal saying:
- “that action turned out better than expected, do more of it”
- or “that action turned out worse than expected, do less of it”
This split is powerful because it keeps the policy update low-variance without forcing the policy to learn everything from raw returns alone.
Why Vanilla Actor-Critic is Fragile

Why basic Actor-Critic can be so fragile and unstable.
In supervised learning: data distribution is fixed.
In RL: the policy defines the data distribution:
- A policy update changes which actions are taken → which states are visited → which data is seen next
Small parameter change ⟹ potentially huge behaviour change
A single large update can completely collapse the training distribution.
Trust Region Policy Optimisation (TRPO)

TRPO: making policy updates more stable by staying in a "trust region".

Constraining KL divergence to keep policy updates from going off the rails.
Step size is much harder to tune in RL than in SL:
- Too small → slow learning
- Too large → catastrophic collapse
TRPO [Schulman et al., 2015]: optimise a surrogate objective using old-policy data, constrained by a hard KL divergence limit:
- Probability ratio: importance sampling correction for using old-policy data
- KL constraint: keeps the update inside a “trust region”
- Solved via Fisher Information Matrix + conjugate gradient — second-order method (expensive)
Proximal Policy Optimisation (PPO)

PPO: a much simpler and more popular alternative to TRPO.
PPO [Schulman et al., 2017]: the practical successor to TRPO.
Step 1: KL Penalty (Soft Constraint)
Replace the hard constraint with a tunable penalty:
Step 2: Clipped Objective (PPO-CLIP) — the standard version

PPO-CLIP: clipping the objective to prevent those dangerous large updates.
Clip the probability ratio directly:
where
Clipping mechanics (typical , clip range ):
| Scenario | Effect |
|---|---|
| , | Clipped — no further incentive to push it higher |
| , | Normal gradient ascent |
| , | Clipped — no further incentive to push it lower |
| , | Normal gradient descent |
Intuition: The ensures the objective stops rewarding changes once the ratio moves too far outside in the helpful direction.
🧠 Deep Dive: Why PPO Can Reuse the Same Batch for Multiple Epochs
Vanilla policy gradient is fragile because once the policy changes, old samples quickly become stale.
PPO’s ratio
explicitly tracks how far the new policy has moved away from the policy that generated the data.
That does two useful things:
- it lets us still learn from trajectories collected by the old policy
- clipping prevents us from exploiting that old data too aggressively
This is why the original PPO paper emphasizes that the method supports multiple epochs of minibatch updates on the same sampled batch while remaining much simpler than TRPO.
Worked Example ():
Action a in state s, advantage A_hat = +2.0 (good action)
pi_old(a|s) = 0.30
pi_new(a|s) = 0.45 -> ratio = 0.45/0.30 = 1.50
Without clipping: L = 1.50 * 2.0 = 3.0
With clip(1.50, 0.8, 1.2) = 1.2:
L = min(1.50*2.0, 1.2*2.0) = min(3.0, 2.4) = 2.4
Update is capped — cannot become too aggressive even for a very good action.
PPO vs. TRPO
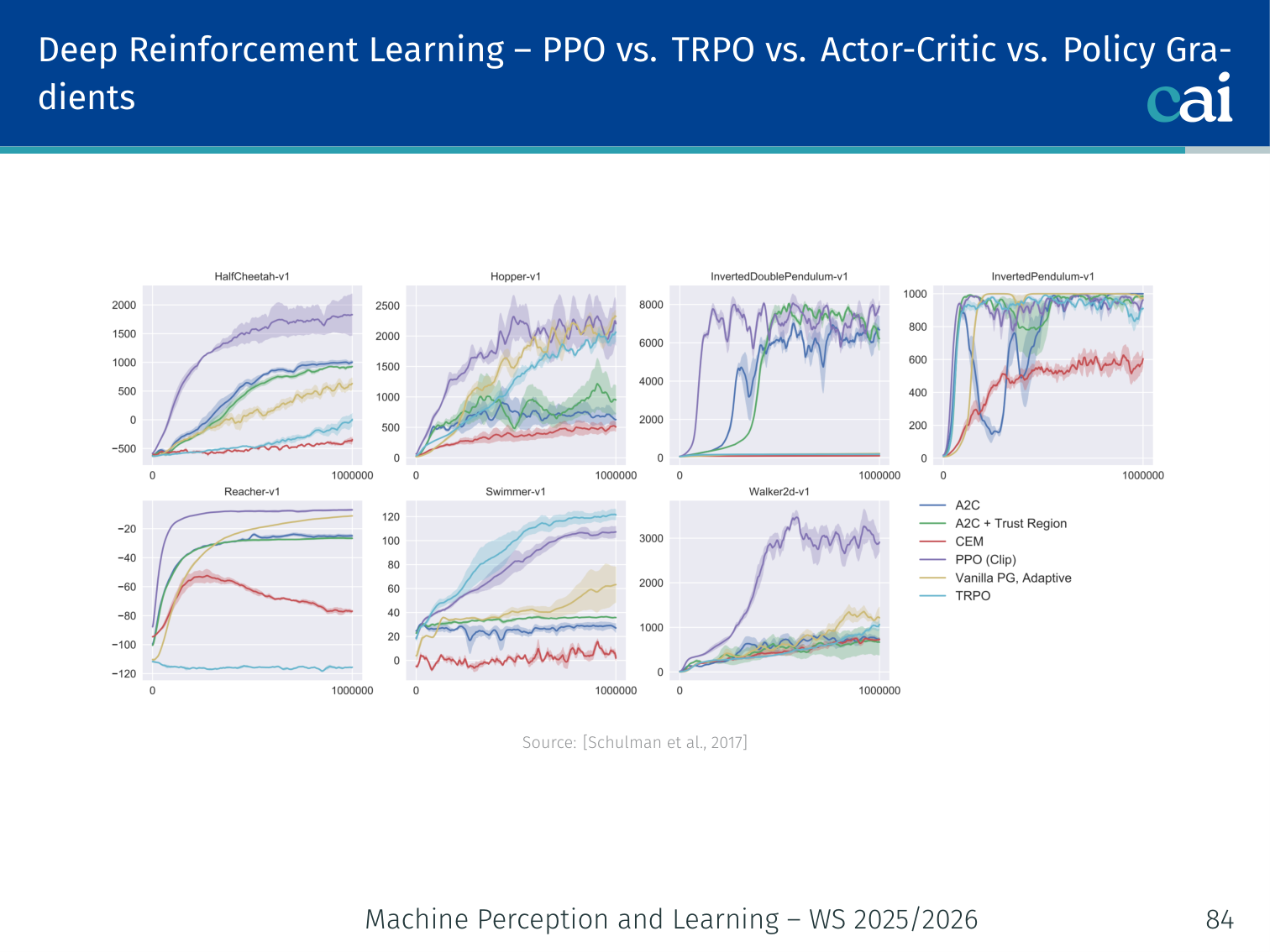
PPO vs. TRPO: weighing performance against complexity.
| Property | TRPO | PPO |
|---|---|---|
| Constraint | Hard KL | Clipped ratio |
| Optimisation order | Second-order (conjugate gradient) | First-order (Adam) |
| Implementation complexity | High | Low |
| Computation cost | Heavy | Lightweight |
| Performance | Good | Comparable or better |
Reinforcement Learning from Human Feedback (RLHF)
Large language models are initially trained with next-token prediction, which teaches them to model text distributions well. But this objective does not directly optimise for what humans actually want: helpfulness, harmlessness, honesty, instruction-following, or style preferences. RLHF addresses this gap by turning human preferences into a learning signal (Ouyang et al., 2022).
Three-Stage Pipeline
1. Supervised Fine-Tuning (SFT)
Start from a pre-trained language model and fine-tune it on human-written demonstrations of good behaviour.
- Input: prompt
- Target: high-quality human response
- Result: a model that can follow instructions reasonably well
2. Reward Model Training
Next, collect human preference comparisons. Annotators are shown two candidate responses for the same prompt and choose the better one.
If is the preferred response and the rejected one, the reward model is trained so that
A common pairwise objective is
so the reward model learns to approximate human preference.
3. RL Fine-Tuning with PPO
Finally, optimise the policy against the reward model using PPO. The objective is not just “maximise reward”, but “maximise reward while staying close to the reference model”:
where:
- is the current policy
- is usually the SFT model
- is the learned reward model
- controls how strongly we penalise deviation from the reference model
Why the KL Penalty Matters
Without the KL term, the model may exploit weaknesses in the reward model and drift toward unnatural text. This is a form of reward hacking.
The KL penalty helps because it:
- keeps the policy close to the original language model
- preserves fluency and general language competence
- prevents the model from chasing spurious high-reward behaviours too aggressively
Example: A reward model might accidentally prefer overly long, overly flattering, or repetitive answers. Without a KL penalty, the policy could exploit this artifact instead of becoming genuinely more helpful.
🧠 Deep Dive: Why RLHF Uses a Per-Token KL “Leash”
In the InstructGPT setup, OpenAI explicitly adds a per-token KL penalty from the SFT model during PPO to reduce over-optimization of the reward model.
That is a very practical design choice. The reward model is only an approximation of human preference, so if the policy is allowed to optimize it too hard, it may discover weird hacks that score well but sound unnatural.
A helpful intuition is to think of the KL term as a leash:
- the reward model pulls the policy toward preferred behavior
- the KL term pulls it back toward the fluent, general-purpose SFT model
Good RLHF needs both forces. If reward dominates completely, the model can become brittle and exploitative. If KL dominates completely, the model barely changes and alignment gains are weak.
RLHF in One Picture
| Stage | Data source | Objective |
|---|---|---|
| SFT | Human demonstrations | Learn to imitate good answers |
| Reward model | Human preference comparisons | Learn a scalar proxy for human judgement |
| RL with PPO | Model-generated responses + reward model | Optimise policy while constraining KL drift |
In short, RLHF combines supervised learning, preference modelling, and reinforcement learning. In practice, the RL stage is usually performed with PPO, which is why PPO became central to instruction-tuning pipelines such as InstructGPT (Ouyang et al., 2022).
PyTorch Implementation: Proximal Policy Optimization (PPO)

A quick look at how to implement PPO in PyTorch.
PPO is an actor-critic algorithm that ensures stable training by limiting how much the policy can change in a single update.
import torch
import torch.nn as nn
from torch.distributions import Categorical
# 1. The Actor-Critic Network
class ActorCritic(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
# --- THE ACTOR (Policy) ---
# Input: State features
# Output: Probability distribution over actions
self.actor = nn.Sequential(
nn.Linear(state_dim, 64),
nn.Tanh(), # Tanh is common in RL for smooth gradients
nn.Linear(64, action_dim),
nn.Softmax(dim=-1) # Ensures action probabilities sum to 1
)
# --- THE CRITIC (Value Function) ---
# Input: State features
# Output: A single scalar V(s) representing expected future reward
self.critic = nn.Sequential(
nn.Linear(state_dim, 64),
nn.Tanh(),
nn.Linear(64, 1)
)
def act(self, state):
"""Used during data collection to pick actions."""
probs = self.actor(state)
# Categorical distribution handles sampling and log-probs for us
dist = Categorical(probs)
action = dist.sample() # Sample action according to policy
return action, dist.log_prob(action)
def evaluate(self, state, action):
"""Used during the update step to evaluate taken actions."""
probs = self.actor(state)
dist = Categorical(probs)
action_logprobs = dist.log_prob(action)
dist_entropy = dist.entropy() # Entropy encourages exploration
state_value = self.critic(state) # V(s)
return action_logprobs, state_value, dist_entropyKey RL Concepts:
- The Actor-Critic Split: The Actor focuses on behavior (what to do), while the Critic focuses on judgment (how good the current state is).
- Log-Probabilities: In RL, we maximize the log-probability of actions that led to high rewards.
- Entropy: High entropy means the policy is “uncertain” and spread out, which is good for exploring different actions. PPO often adds an entropy bonus to the loss to prevent the model from becoming too greedy too early.
Notable Achievements
| Achievement | Algorithm | Reference |
|---|---|---|
| Atari at superhuman level from raw pixels | DQN | Mnih et al., 2015 |
| Mastering the game of Go | AlphaGo (policy/value net + MCTS) | Silver et al., 2016 |
| Locomotion and continuous control | PPO / TRPO | Schulman et al., 2017 |
| Grandmaster StarCraft II | AlphaStar (multi-agent RL) | Vinyals et al., 2019 |
| Fine-tuning LLMs via human feedback (RLHF) | PPO | Ouyang et al., 2022 |
Summary
Algorithms
| Algorithm | Family | Key Idea |
|---|---|---|
| Value Iteration | DP | Bellman optimality as iterative update; full model required |
| Policy Iteration | DP | Alternate policy eval + greedy improvement; full model required |
| SARSA | TD, on-policy | Q updates using actual next action from same policy |
| Q-Learning | TD, off-policy | Q updates using greedy max; converges to |
| DQN | Deep value-based | Neural Q-function + experience replay + target network |
| REINFORCE | Policy gradient (MC) | Full trajectory rollouts; high variance |
| Actor-Critic | Policy gradient + TD | TD-error as advantage; bootstrapped; lower variance |
| TRPO | Actor-Critic | Hard KL trust region; second-order optimisation |
| PPO | Actor-Critic | Clipped ratio; first-order; most widely used |
Key Concepts
| Concept | One-line summary |
|---|---|
| MDP | Formal framework: |
| Bellman equation | = immediate reward + discounted value of next state |
| Bootstrapping | Use current value estimate as target; update before episode ends |
| On-policy vs off-policy | Same vs different policy for data collection and updates |
| Advantage | How much better action is vs average: |
| Trust region | Constrain policy updates to stay close to old policy |
References
- Albrecht, Christianos, Schäfer. Multi-Agent Reinforcement Learning: Foundations and Modern Approaches. MIT Press, 2024.
- Mnih et al. Playing Atari with Deep Reinforcement Learning. arXiv:1312.5602, 2013.
- Mnih et al. Human-level control through deep reinforcement learning. Nature, 518:529–533, 2015.
- Ouyang et al. (2022) — Training language models to follow instructions with human feedback. NeurIPS.
- Schulman. Deep Reinforcement Learning via Policy Optimization (tutorial). 2017.
- Schulman, Levine, Abbeel, Jordan, Moritz. Trust Region Policy Optimization. ICML, 2015.
- Schulman, Wolski, Dhariwal, Radford, Klimov. Proximal Policy Optimization Algorithms. arXiv:1707.06347, 2017.
- Silver et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016.
- Vinyals et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 2019.
Applied Exam Focus
- Exploration vs. Exploitation: The agent must balance trying new actions (-greedy) with using what it already knows to get high rewards.
- Bellman Equation: Decomposes the value of a state into the immediate reward plus the discounted value of the next state.
- Q-Learning: An Off-policy algorithm that learns the optimal action-value function regardless of the agent’s current behavior.
Previous: L10 — GANs | Back to MPL Index | Next: (y-12) Diffusion | (y) Return to Notes | (y) Return to Home